Introduction 🔗
Analysis is an integral part of both indexing and searching operations in Lucene. It involves several processes including splitting the text into tokens, removing stop words, handling synonyms and phonetics, etc. Both the documents and queries are analyzed using the same analyzer, with exceptions in some cases.
Anatomy of an Analyzer 🔗
An analyzer is responsible for taking in a Reader and returning a TokenStream.
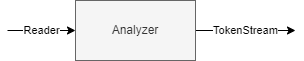
An Analyzer mainly consists of 3 components
- CharFilter
- Tokenizer
- Token Filter
CharFilter 🔗
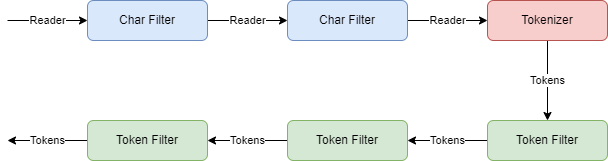
CharFilter can be used to perform operations on the data before tokenizing it. CharFilter operates on the Reader object rather than the TokenStream Object. Some of the operations that can be performed using CharFilter are : Strip HTML elements from the input. Replace specific characters. Pattern match and replace.
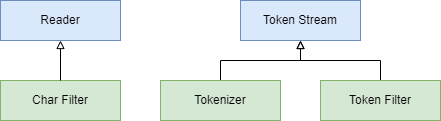
A CharFilter itself is a subclass of Reader while Tokenizer and TokenFilter are subclasses of TokenStream.
Tokenizer 🔗
A tokenizer is responsible for splitting the text into tokens. Various tokenizers are available that use different strategies to tokenize the text. For instance, a WhitespaceTokenizer splits the text on whitespaces. StandardTokenizer should suffice the needs of most users.
TokenFilter 🔗
TokenFilter operates on tokens. Tokens that are spit out by Tokenizer are passed through a series of token filters. Built-in token filters are available that can perform a wide variety of jobs. Synonym handling Trimming tokens Handling phonetics Removing stopwords Producing ngrams
In a typical application, a Reader is passed through a series of char filters, and then a single tokenizer and a series of token filters.